This is Part I of a series of blog post about how we work with legacy code.
About half of our work consists of creating new applications from scratch. It’s nice because then we can take care of the whole stack.
The other half consists of extending an already-started application.
This time we have to step into other people shoes.
Having done it for a couple of years, we came up with a process for this exercise.
This series of post will try to decrypt the art of entering legacy projects.
Some parts might be Ruby-on-Rails-centric, but most of the takeaways should be useful for any kind of projects.
What is the discovery?
We never try to jump straight into a project and make important changes on the source code without a discovery phase.
In an ideal world, the previous developer/team would have left a project in perfect working order. Documentation of the different parts/components would be available and the test suite would be extensive.
Unfortunately, let’s face it, that’s rarely the case.
Depending on the project size, the discovery phase can last between 10 and 20 days.
Those days are important for all the parties involved in the process.
Developers will have time to dive into the code structure and conventions, libraries used, external services used, and to document the application internals.
The project manager will help the client transition into a new team and carry out the development/feature selection process.
The client will get know how we work, and what is expected from them.
How to make a productive discovery phase
![]()
What we like to do during the discovery phase is reserve a couple of days that are feature-free for the developers.
This time is used for the schema mapping, and the external service hookup (more on that point later on).
During this phase, the project manager and the client will draw a list of quick wins.
These quick wins are usually tiny to small features/bugs, with a very low risk, within all sections of the application.
Once the mapping and documentation is complete, we start to work our way through those quick wins during the remaining time of the discovery phase.
The quick wins serve 2 purposes:
- They make your discovery phase productive, ie: You will actually have something done in the code.
- They allow developers to dig into various part of the code, from the front-end to the back-end, and might bring some larger problems into the spotlight.
They will also ensure that the developers deploy something daily.
This is crucial on the development point of view (it might require us to set up a staging server, learn a new deployment strategy and so on). On the project management point of view, as we require our clients to be testing new features on a daily basis, they can hopefully start this habit now.
Hooking onto external services
It is possible that the previous team used some external tools to help manage the project.
If that’s the case, then we usually try to keep them, as long as they make sense with our stack.
If that’s not the case, the first 3 external apps we hook up into the app are usually:
Code Climate
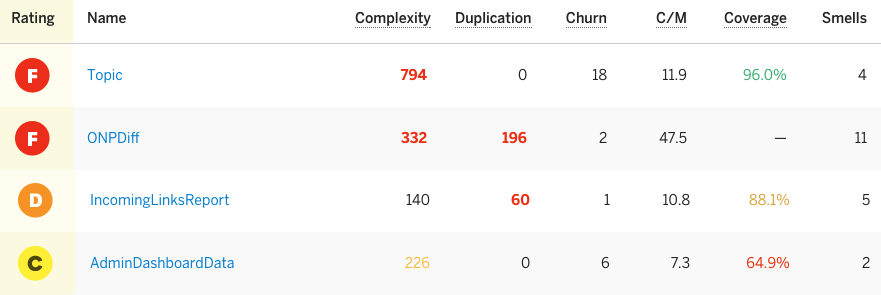
Code Climate, helps us quickly analyse the code quality and complexity. Hooking it up will take 5 minutes and can save days of headaches in the long run.
An exception tracker
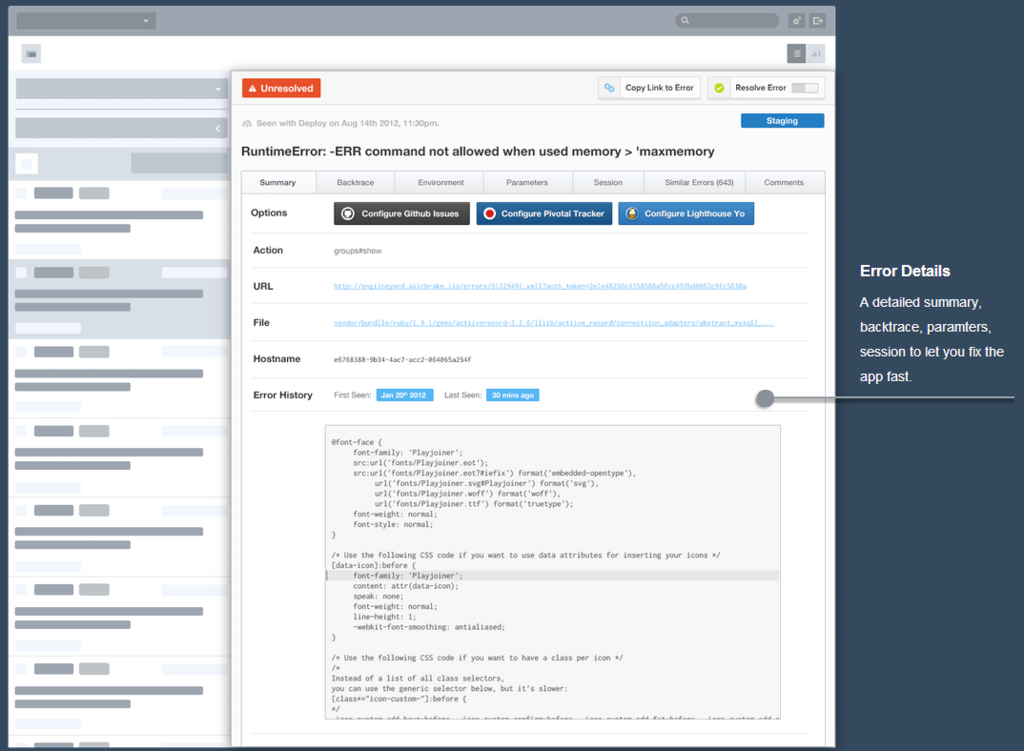
The aim of an exception tracker is to notify you when a user experiences an error with your app or website.
It’s surprising how many projects are not shielded with an exception tracker.
We will usually set up Airbrake or BugSnag for both the staging and production environment. Depending on project, this can also be an eye-opener on the code status.
Continuous Integration Server
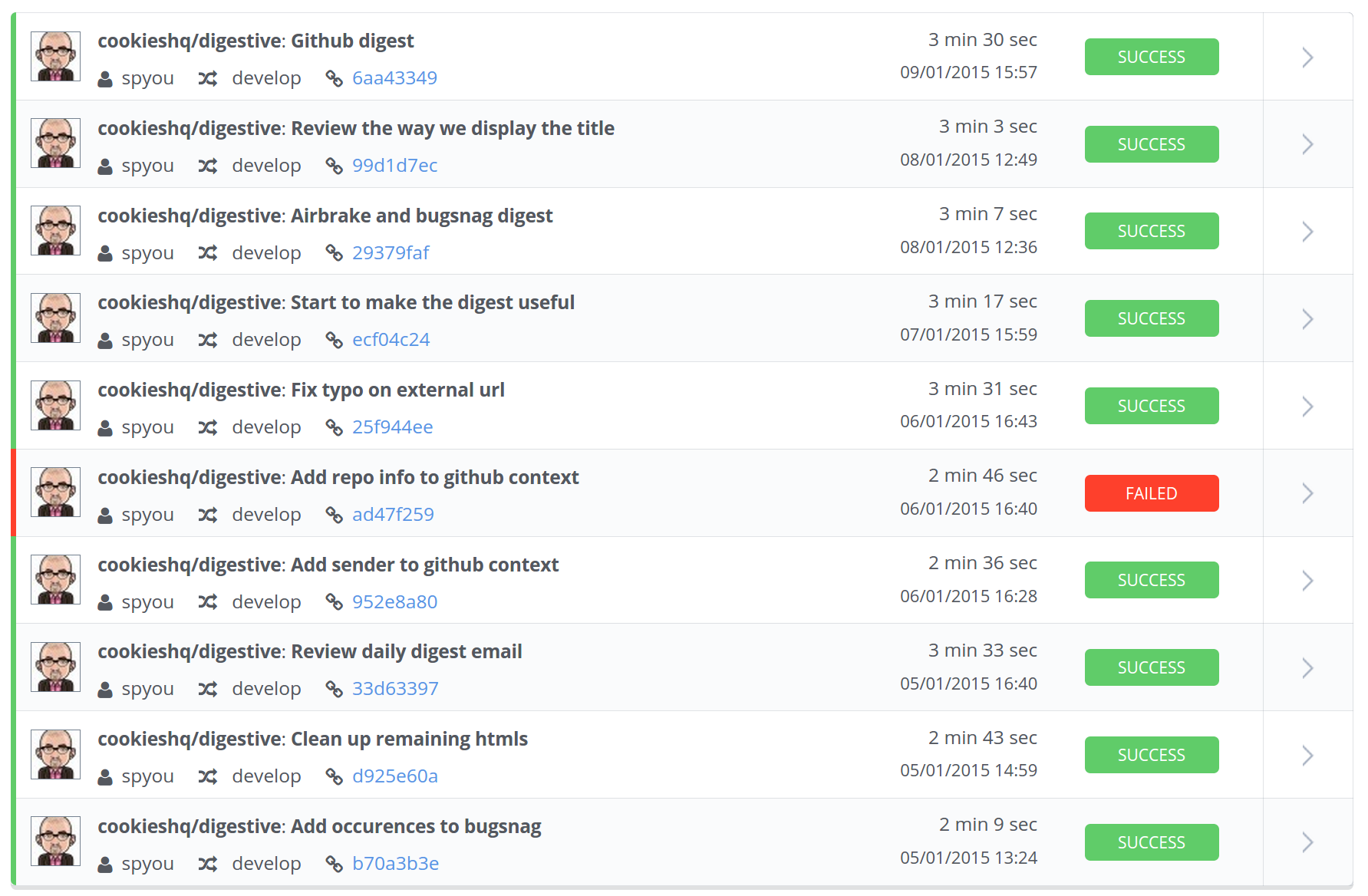
These days we rarely deploy manually and will leave this task to our CI Server. We even have it setup to mark which cards were deployed on our project management software (read more about this on a previous blog post).
Our de facto CI tool these days is Codeship. Dead easy to set up and just works.
Planning the full speed iteration
The discovery phase is usually a love-it-or-hate-it phase. But whatever is discovered during this phase should notify the project owner as this could have an impact on the upcoming iteration (think security issues, large discovered bugs …).
When updating the project, we like to add a simple severity level to the issues we found.
The fixes, if not done during the discovery phase, should be planned for as soon as possible in the future iterations.
If you have already planned the feature to be developed in the upcoming iteration, it’s also usually a good time to slow down on the different affected areas and make notes on how the future feature will be developed.
What’s next
Another big part of discovery in new projects is discovering the test suite (if there is any), so I will dedicate the Part II of this series to how we work with legacy tests.
In the mean time, don’t hesitate to leave you questions in comments if you want to know more about our discovery phase.
